Université d’été | Bi-licence "Lettres – Informatique" | Ateliers
PAGE ACCUEIL
Entretien autour du ARTFL Project et de PhiloLogic4, avec Clovis Gladstone, Robert Morrissey et Glenn Roe
15 Décembre 2017
Entretien autour du ARTFL Project et de PhiloLogic4, avec Clovis Gladstone, Robert Morrissey et Glenn Roe

L’ARTFL existe depuis 1982, pouvez-vous rappeler l’origine et les différentes étapes de ce projet jusqu’à PhiloLogic4 ?
Robert Morrissey
Tout a commencé lors de l’élaboration de ma thèse de doctorat sur La Rêverie jusqu’à Rousseau (Lexington, French Forum publishers, 1984). Je recherchais des occurrences du mot « rêverie » ; on me parla du laboratoire du Trésor de la langue française situé à Nancy, et de l’immense concordance qui y était en chantier. J’avais justement besoin d’interroger un important corpus de textes. M. Paul Imbs, fondateur du TLF, m’a réservé à moi – petit étudiant en thèse – un accueil exceptionnel et j’ai pu en effet consulter la concordance imprimée qui existait uniquement dans le laboratoire TLF. C’est là que j’ai compris toute l’importance que pouvait avoir un tel corpus pour le rayonnement de la langue française et pour le monde de la recherche. En discutant avec lui, j’ai conçu l’idée de mettre en place, dans le cadre d’une collaboration entre l’Université de Chicago et le CNRS, un outil interactif destiné aux universités nord-américaines. La mise en place de ce dispositif fut longue et j’exprime toute ma reconnaissance à Bernard Quémada qui a succédé à Paul Imbs à la direction du TLF, et qui a porté un appui indéfectible à ce projet. Le premier outil que nous avons développé était plutôt primitif : il permettait d’interroger, sur commande, les occurrences d’un mot chez un auteur précis. À l’époque la requête devait être formulée par téléphone et nous répondions par courrier électronique. L’invention du web, comme vous pouvez l’imaginer, a tout changé et nous a permis de concevoir une première version de PhiloLogic qui donnait lieu à une interactivité beaucoup plus grande, à une meilleure accessibilité des textes et à une plus grande complexité dans les requêtes. Le perfectionnement d’un ensemble de logiciels qui multiplient les manières d’explorer les textes, de rendre une grande diversité de corpus accessibles à la communauté des chercheurs reste au cœur de notre mission. À l’origine, notre base FRANTEXT comptait 1600 textes. Ce nombre s’élève aujourd’hui à peu près à 3600. C’est donc une base qui réunit un large échantillon des œuvres canoniques de la littérature française. Une autre priorité s’est imposée avec la multiplication de nos bases de données : la création de logiciels open source les plus universels possibles, pouvant interroger des textes aussi différents que La Chanson de Roland et Le Rouge et le Noir, et traiter des langues comme le latin, le grec, l’italien et même le serbo-croate. Aujourd’hui nous sommes arrivés à la version 4 de notre logiciel PhiloLogic4
En quoi PhiloLogic4 se distingue-t-il des logiciels précédents ?
Glenn Roe
Avec PhiloLogic4, nous avons tenu compte du fait que les chercheurs qui utilisent nos bases de données aujourd’hui ont tendance à fonctionner comme s’il s’agissait d’une recherche sur Google. Leurs requêtes partent en général d’un mot clef et évoluent en fonction des résultats délivrés par le moteur de recherche. PhiloLogic4 reprend ce principe : une recherche sur les occurrences du mot « Charlemagne », dans la nouvelle version de l’ARTFL Encyclopédie, par exemple, aboutit à une liste de 455 occurrences, qu’il est désormais possible de filtrer de manière interactive : par matière, par entrée, par auteur, etc., sans jamais perdre de vue le point de départ de la recherche.
Clovis Gladstone
Le principe de la navigation à facettes permet en effet de faire évoluer une recherche d’un simple clic. Avec PhiloLogic3, il fallait anticiper tous les filtres (par matière, par auteur, etc.) et tout recommencer à chaque nouvelle recherche. PhiloLogic4 fait apparaître les métadonnées en même temps que les textes et ces métadonnées sont interrogeables. On peut également générer des nuages de mots, ce qui rend l’étude des fréquences plus intuitive.
Glenn Roe
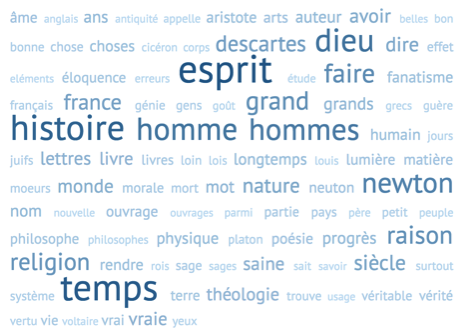
Par exemple, dans le contexte de notre collaboration avec la Voltaire Foundation, à l’Université d’Oxford, on peut désormais utiliser PhiloLogic4 pour interroger l’ensemble des œuvres de Voltaire. Voici un nuage de collocations, c’est-à-dire d'association de mots, avec le terme « philosophie », qui apparaît 914 fois dans la base de données TOUT Voltaire :
Dans « La littérature à l’âge des algorithmes », un article que vous avez cosigné dans la RHLF, n° 3, 2016, vous réfléchissez à la part de la machine dans la production des résultats d’une recherche et aux risques de « perte d’immédiateté » que cette évolution représente.
Robert Morrissey
La réflexion est apparue avec le big data : si je fais ma recherche sur le mot « rêverie » et que la recherche aboutit à 5000 occurrences, je peux à la rigueur prendre en charge le traitement des résultats tout seul. Mais avec les bases actuelles, les résultats se comptent parfois en centaines de milliers d’occurrences, et personne ne peut contrôler intégralement une telle masse d’informations. Notre travail sur la base ECCO (Eighteenth Century Collections Online), par exemple, qui rassemble tous les livres publiés en Angleterre au XVIIIe siècle, s’effectue à une tout autre échelle. Il s’agit d’un corpus à la fois cohérent et immense. Une extension de PhiloLogic4, PhiloLine, nous a permis de repérer les réemplois textuels dans cette grande base de données. PhiloLine propose de même une navigation à facettes pour faciliter une exploration plus en profondeur des résultats. Dans le débat entre la « lecture à distance » et la « lecture intensive », nous sommes du côté de ceux qui pensent qu’il faut rester proche du texte ou plutôt qu’il faut toujours pouvoir revenir au texte.
Les humanités numériques permettent-elles de renouveler l’approche de l’Encyclopédie ?
Robert Morrissey
Tout à fait ! Comme vous le savez, la mise en ligne de l'Encyclopédie sous PhiloLogic, il y a maintenant une vingtaine d'années, a non seulement rendu ce texte facilement accessible à la communauté des chercheurs, mais elle a permis d'ouvrir de nouvelles perspectives de recherche, qui impliquent, il est vrai, une certaine violence faite au texte. Avec l'outil informatique, chaque mot devient un point d'entrée dans l’Encyclopédie, et il y en a plus de 22 millions. En d'autres termes, il est possible de mobiliser l’intégralité des articles de l’Encyclopédie, dans chaque recherche. Ces possibilités ont à leur tour nourri notre réflexion sur la façon dont notre logiciel PhiloLogic devrait fonctionner sur les bases de données textuelles d'une manière générale. On peut dire que PhiloLogic4 est le fruit de ces réflexions. Cette synergie illustre les apports des humanités numériques
Clovis Gladstone
Oui, et nous avons aussi profité des avancées dans le domaine du data-mining pour entreprendre des expériences d'apprentissage automatique sur le texte de l’Encyclopédie. Il se trouve en effet que le système de classification de l’Encyclopédie est une véritable mine de savoir pour ces algorithmes d'apprentissage automatique. Ainsi, nous avons dans un premier temps construit un classificateur automatique a partir des 60 000 articles classés afin de catégoriser les quelques 17 000 articles non classés du texte, nous donnant pour la première fois une vision d'ensemble sur les thématiques traitées dans ces articles. Bien entendu, cette catégorisation est loin d’être parfaite, et demeure purement basée sur des calculs statistiques. Mais elle offre de nouveaux points d’entrée potentiels sur le texte, une incitation à plonger dans ces articles, à les envisager de façon différente. Nous nous sommes aussi inspirés d’algorithmes tirés de la bio-informatique afin de repérer automatiquement les réemplois dans l’Encyclopédie de textes antérieurs, nous donnant cette fois une meilleure idée des sources réelles du texte. Nous avons bien sûr mis ces différents outils que nous avons développés à la disposition des chercheurs, espérant ainsi promouvoir une multiplication des perspectives sur l’Encyclopédie.
La base de données ECCO, qui réunit l’intégralité des publications en Angleterre au XVIIIe siècle, permet d’étudier un « système culturel ». Pouvez-vous expliquer cette notion et préciser en quoi a consisté votre recherche sur ce corpus ?
Robert Morrissey
Il est très rare d’avoir à sa disposition la quasi-totalité des textes publiés à une période donnée, en l’occurrence tout le XVIIIe siècle. Interroger un tel ensemble revient à étudier un système culturel. On a constaté que la Bible était une référence omniprésente dans les publications, très loin devant les auteurs latins et même devant Shakespeare, qui est l’écrivain national le plus cité. On se doutait bien que la Bible était importante dans la culture anglaise et dans l’Angleterre du XVIIIe siècle, mais nous avons tout de même été frappé par l’ampleur du phénomène. La même recherche dans un corpus d’œuvres littéraires sélectionnées comme FRANTEXT, par exemple, aboutit à un résultat très différent : l’importance de la Bible y est bien moindre. De ce point de vue, une recherche dans ECCO et une recherche dans FRANTEXT ne sont pas de même nature : il y a une différence fondamentale d’échelle. D’où l’expression « système culturel », qui nous rapproche des sciences sociales. L’écart entre les bases ouvre d’ailleurs des pistes de réflexions intéressantes dans le domaine de l’histoire littéraire, sur la place des écrivains dans nos sociétés, sur la valeur de représentativité de la littérature, sur la formation des canons littéraires…
Glenn Roe
C’est en effet un changement de paradigme. Dans la base de données ECCO-TCP (Text Creation Partnership), par exemple, une base de données créée dans un esprit semblable à celui de FRANTEXT, qui se compose d’une sélection d’œuvres considérées comme canoniques, l’importance de la Bible est également beaucoup moins forte que dans ECCO. Notre projet, à l’origine, était de travailler sur les lieux communs (en anglais commonplacing), à travers l’étude du réemploi de certaines expressions ou de certains passages à très grande échelle. Mais le « système culturel de réutilisation » auquel nous avons affaire dépasse largement le champ des lieux communs tel que nous le comprenons en littérature.
Comment est née la collaboration avec le Labex OBVIL autour du projet « Use and reuse. Explorer l’héritage culturel du dix-huitième siècle », dans lequel la BnF est également impliquée ?
Robert Morrissey
Nous étions en contact avec Jean-Gabriel Ganascia (UPMC, Labex Obvil), qui a mis au point le logiciel d’alignement de séquences MEDITE, dans le cadre d’une réflexion que nous menions sur les citations et sur les problèmes d’autorité dans l’Encyclopédie. Nous avons commencé à réfléchir ensemble à une manière originale d’aborder ces questions de réemplois, à la façon de les repérer, de les comparer dans une base comme ECCO et de les trier dans le but de cerner des champs de recherche. Didier Alexandre (Paris-Sorbonne, Labex Obvil) a eu l’idée d’impliquer la BnF, qui a mis à notre disposition le corpus BNF-TGB, puisé dans le corpus de GALLICA et qui représente environ 130 000 textes. Bien entendu, là encore, ECCO et BNF-TGB ne sont pas de même nature. Mais comme les numérisations de la BnF sont plutôt orientées vers le XIXe siècle, la possibilité d’étudier la fortune d’une expression, d’une série de citations ou d’une idée sur une période de deux siècles, XVIIIe-XIXe siècles, à partir de deux corpus immenses, ouvre, j’en suis convaincu, des perspectives très intéressantes pour la recherche.
Propos recueillis par Romain Jalabert
 Clovis Gladstone
Clovis Gladstone
 Robert Morrissey
Robert Morrissey
 Glenn Roe
Glenn Roe