Université d’été | Bi-licence "Lettres – Informatique" | Ateliers
PAGE ACCUEIL
XML stats
21 Juin 2015
XML stats
- Frédéric Glorieux
XML stats est un outil pédagogique et professionnel utile à l’exploration rapide d’un ou plusieurs fichiers XML. Il a été commencé en 2012 par Frédéric Glorieux pour une étude sur le balisage des dictionnaires, l’outil continue sa vie à l’OBVIL. Il fournit différentes statistiques relatives aux balises et au texte qu’elles contiennent, notamment la liste des mots les plus fréquents pour une balise. Cet outil en ligne est utilisé par l’OBVIL lors de sessions de formation XML, ainsi que par l’équipe d’édition XML pour rapidement détecter des erreurs de balisage (intrus, sémantique). Les informations extraites sont orientée vers l’analyse de document textuels, notamment TEI (mais aussi, EAD). On peut ainsi compter séparément certains éléments selon la valeur d’un attribut (@type, @xml:lang…). Le logiciel introduit différents indices, par exemple la “segmentation”, c’est à dire la taille moyenne d’un segment sans interruption de balises (en caractères). Cette métrique élémentaire est assez intéressante pour mesurer la complexité d’un texte structuré.
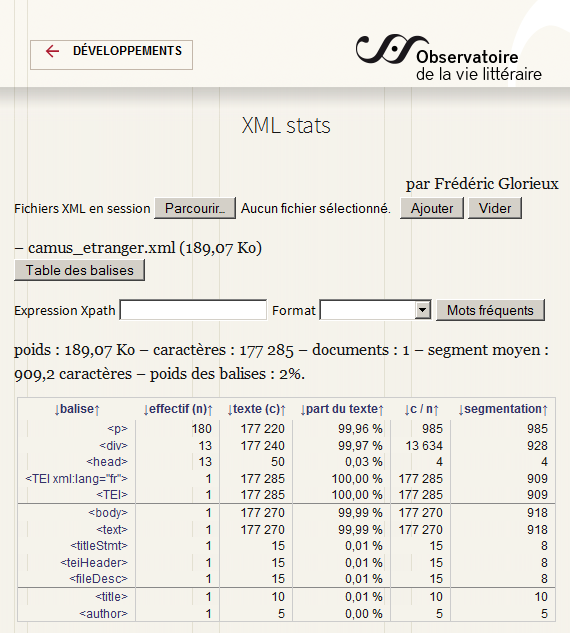
- Descartes, Discours de la méthode : 1251 c. (paragraphes)
- Stendhal, le Rouge et le noir : 168 c. (paragraphes et dialogues)
- Racine, Phèdre : 40 c. (vers, personnages)
- Wikipedia (sélection d’articles) : 40 c. (titres, paragraphes, liens…)
- Littré : 35 c.
- Petit Robert : 21 c.
- Liddell-Scott-Jones (dictionnaire de grec ancien) : 15 c.